Platform Monitoring
v2025.04.01Earlier in the month, we hastily put together external monitoring code for our platform. This week we fixed it.

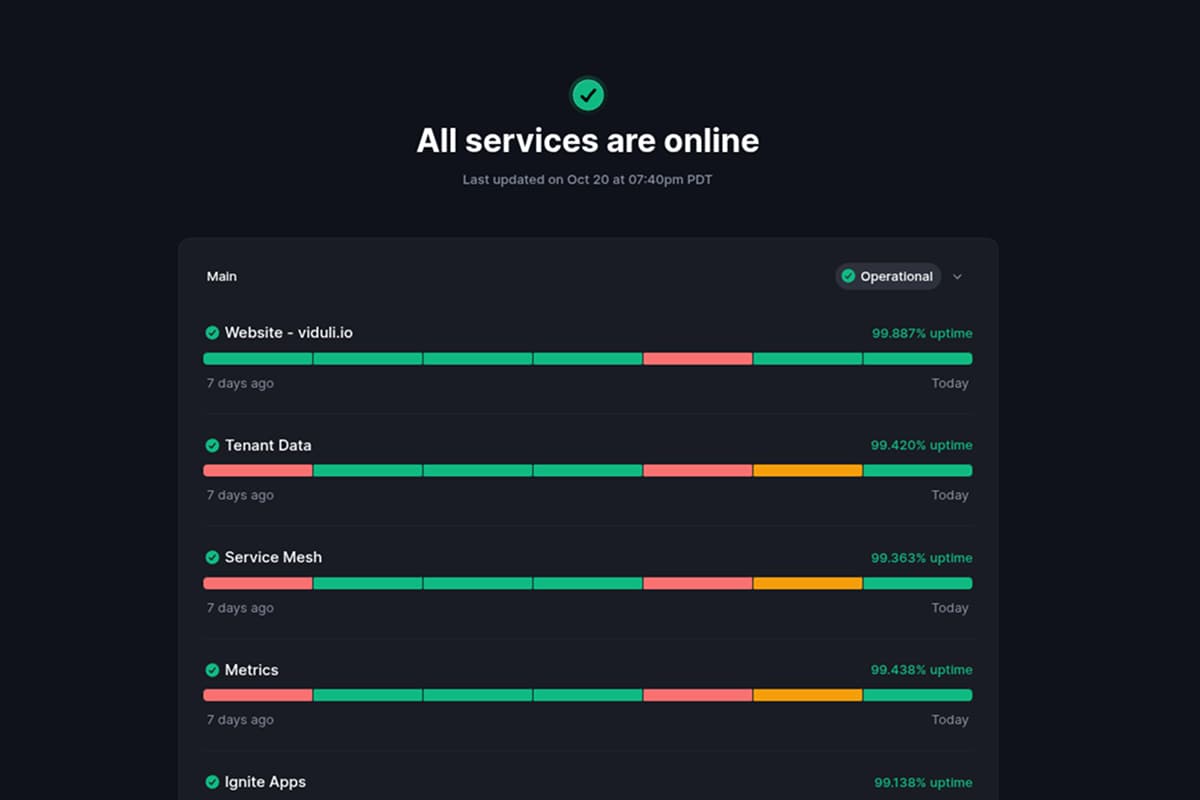
Earlier this month, we quickly put together health check code to get our platform monitoring live in production. While it worked, it had some significant shortcomings. The code was originally designed to run in a worker pool but was repurposed to run on the main thread, and it didn't support concurrency. Needless to say, that didn't go well. It blocked all subsequent requests to the server and triggered Kubernetes to restart the pod.
We've now rewritten our health check system to be fully async and run in thread pools. Our health checks fully emulate the actions a user would take on the platform, providing the best possible assurances to our end users. We also fixed a critical issue where hard-coded resource IDs were causing concurrency conflicts - resource IDs are now generated dynamically. The result? Our health checks now support n-level concurrency instead of being limited to a single instance.
But, the platform monitoring saga is not over yet. Our Ignite Apps deployment check intermittently fails. We are investigating now. Stay tuned for more updates!